
代码已然更新,网站降低了一些headers的反爬限制,简单更改后才能继续使用。
现在的代码,把mongodb保存部份#掉了,直接运行能够保存图片
如果保存图片报错,建立一个文件夹F:\spider\picture\zhainan2\,建立到最后这个zhainan2文件夹,下载的图片就会保存在这儿,需要更改的话,在代码中找到相应部份修改。
——————————————————————————————
这一系列的爬虫,都是网上不存在,自己找到的感兴趣的网站进行剖析爬取。
也当成自己的动手实践吧,GO!
爬取网页:百度搜索“宅男女神”,第一个搜索结果。
(收藏数是点赞数的十倍!这你敢信?顺便求个赞吧,哈。)
背景:
没有编程基础的金融学专业大三中学生。只通过 @静觅 的爬虫课程,学习了爬虫知识
愿景:
在今年下学期结束前能完成一个数据爬虫,分析,可视化,web为一体的项目。
目的:
爬取网站大量图片对于抓取的图片进行分类保存
参考学习资料:
如何学习Python爬虫[入门篇]?(强烈推荐!十分有用!里面有关python学习线路很适宜大众,爬虫的相关学习难度也很适中)Python3 教程 | 菜鸟教程快速上手 - Requests 2.18.1 文档Beautiful Soup 4.2.0 文档
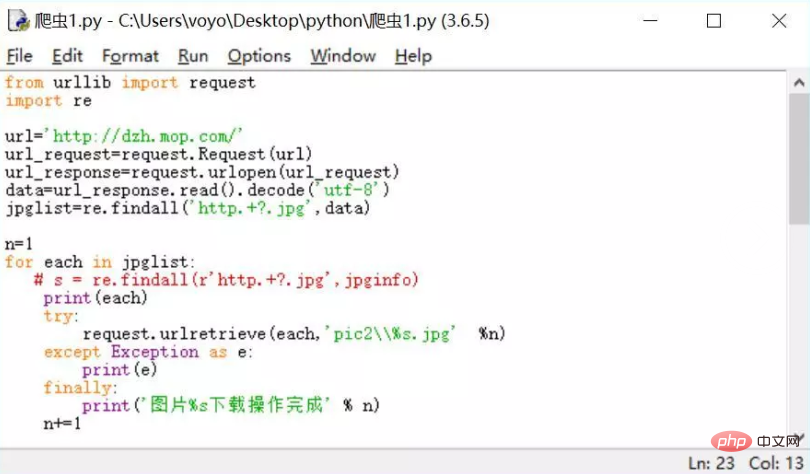
环境配置:
系统环境:WIN8编译环境:Python3.5所需库:requests、re、os、pymongo、Beatifulsoup、timeIDE:Pycharm
学前疑问:
如何找到各个图片的地址插口怎么遍历图片地址,批量保存图片怎样保证爬虫能常年运行不中断
分析网站:(最重要一部分!)
作为一个爬虫菜鸟,分析网站思路的学习是我之前学习过程中耗费时间精力最大的部份。这次要爬取的网站,来自于百度搜索,宅男女神的第一个结果网站。首先打开F12,观察界面中各个图集的入口信息,发现href标签中带有信息/g/24699/,而前面这个五位数是决定图集不同的主要诱因。而且,越是最新的图片,数字越大。网站是通过时间差别来给图集编号,那么只要我遍历所有编号,就能获得所有图片集地址信息了。通过自动测试发觉,按次序编号,不一定存在图集,所有须要一个函数来筛选出有效的详情图片集网址。
获得详情页地址之后,分析详情页。我们须要抓取,详情页中的标题,图片地址,图片个数。观察图片地址发觉, :85/gallery/25253/24581/s/030.jpg ,图片的来源格式类似于前面这个链接,同个图集下,除了结尾的三位数030不会改变,其他地方不变。通过获得图片集图片个数,确定有效图片范围,再通过获得图片集地址的固定要素,构造图片集内所有图片的获得链接。
获得图片链接后,只须要保存访问图片链接的response.content,即可实现图片下载保存。通过os库进行文件夹创建,分类保存。再设置格式,保存至MONGODB数据库

具体一剖析,是不是发觉挺简单的!虽然,在崔大视频上面好多爬虫的网站都带有一些难度,比如动态网站,今日头条,里面的图片链接信息都会比较隐蔽,需要多多发觉能够找到。但是,这次的这个网站爬取难度还是十分低的,只须要思路清楚,接下来就是自己实现过程中的各类小问题的解决,多查百度,就能搞定了。
这个爬虫思路还有改善空间,比如说有效图片地址,可以单独设置一个py文件,去运行,保存的地址都是有效地址,就无需自己从10000遍历到30000这么多了。提取之后,遍历有效地址列表就好了。因为爬取量比较大,还可以加上多线程,加快运行速率。
——————————————————————————————————————
代码放到GIT,有须要的自取。
点击这儿
代码已然是纯傻蛋式,只要有requests和beautifulsou这两个库,就能开始手动运行保存。
如果要自己更改爬取范围,贼更改代码最上方的start和end,自己打开网站找到须要爬取的图集,或者直接遍历从10000-30000之间。
成果:(吐槽两句,之前居然被举报,知乎说违背了法律法规,那还是高调一些吧。)
运行了几十分钟,就抓了5000多张图片。
运行久一些,整个网站所有图片你都能抓出来。
如果须要非常图片类型分类的话,可以写一个爬取网站中指定分类下图集链接,再遍历爬取。
再放上之前的爬虫文章,可以参照学习一下。
利用Requests+正则表达式爬取猫眼电影,学习全过程记录与感受。
零基础爬虫学习全记录2:今日头条指定搜索内容下的所有图集图片保存——图片采集小程序
零基础爬虫学习全记录3:利用selenium爬取天猫商品的基本信息
你对你自己要求的的学习目标,完成了吗?
如果还未完成,如果你心动的话。
关注我知乎~
我会继续学习和总结,希望能给你带来一些帮助。
与你们自勉,继续努力!欢迎私信交流~
觉得这篇文章对你有帮助的话,帮忙点个赞~
这也是我动力的来源,谢谢诸位。
这里有个Q群541809771,由 @路人乙 创建,群里有许多人正在学习的路上,欢迎诸位前来讨论,互相监督,互相进步。群里每晚都有人活跃哦~
最后,祝诸位天天好心情~!
