
短链接,通俗来说,就是将长的URL网址,通过程序估算等方法,转换为简略的网址字符串。
大家常常会收到一些莫名的营销邮件,里面有一个十分短的链接让你跳转。新浪微博由于限制字数,所以也会时常看到这些看着不像网址的网址。短链的盛行应当就是微博限制字数唤起了你们的创造力。
如果创建一个短链系统,我们应当做哪些呢?
将长链接变为短链;
用户访问短链接,会跳转到正确的长链接起来。
查找到对应的长网址,并跳转到对应的页面。
短链生成方式短码通常是由[a - z, A - Z, 0 - 9]这62 个字母或数字组成,短码的宽度也可以自定义,但通常不超过8位。比较常用的都是6位,6位的短码早已能有568亿种的组合:(26+26+10)^6 = 56800235584,已满足绝大多数的使用场景。
目前比较流行的生成短码方式有:自增id、摘要算法、普通随机数。
自增id该方式是一种无碰撞的方式,原理是,每新增一个短码,就在先前添加的短码id基础上加1,然后将这个10进制的id值,转化成一个62补码的字符串。
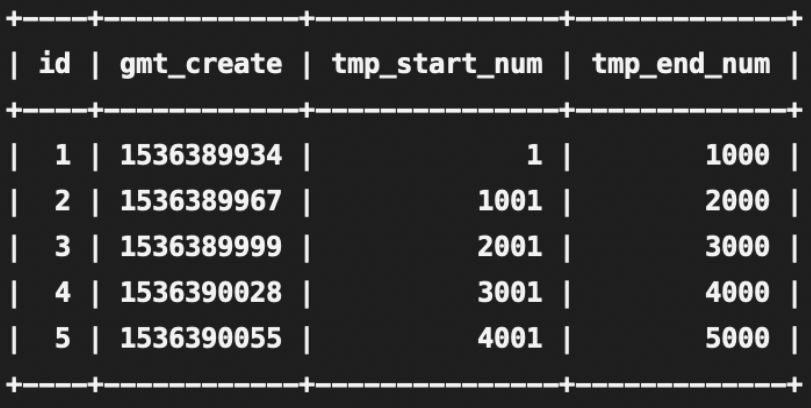
一般借助数据表中的自增id来完成:每次先查询数据表中的自增id最大值max,那么须要插入的长网址对应自增id值就是 max+1,将max+1转成62补码即可得到短码。
但是短码 id 是从一位宽度开始递增,短码的厚度不固定,不过可以用 id 从指定的数字开始递增的形式来处理,确保所有的短码宽度都一致。
同时,生成的短码是有序的,可能会有安全的问题,可以将生成的短码id,结合长网址等其他关键字,进行md5运算生成最后的短码。
摘要算法摘要算法又称哈希算法,它表示输入任意宽度的数据,输出固定宽度的数据。相同的输入数据仍然得到相同的输出,不同的输入数据尽量得到不同的输出。
算法过程:
将长网址md5生成32位签名串,分为4段, 每段8个字节;
对这四段循环处理, 取8个字节, 将他看成16进制串与0x3fffffff(30位1)与操作, 即超过30位的忽视处理;
这30位分成6段, 每5位的数字作为字母表的索引取得特定字符, 依次进行获得6位字符串;
总的md5串可以获得4个6位串;取上面的任意一个就可作为这个长url的短url地址;
这种算法,虽然会生成4个,但是依然存在重复概率。
虽然概率很小,但是该方式仍然存在碰撞的可能性,解决冲突会比较麻烦。不过该方式生成的短码位数是固定的,也不存在连续生成的短码有序的情况。
普通随机数该方式是从62个字符串中随机取出一个6位短码的组合,然后去数据库中查询该短码是否已存在。如果已存在,就继续循环该方式重新获取短码,否则就直接返回。
该方式是最简单的一种实现,不过因为Math.round()方法生成的随机数属于伪随机数,碰撞的可能性也不小。在数据比较多的情况下,可能会循环很多次,才能生成一个不冲突的短码。
算法剖析以上算法优劣我们一个一个来剖析。
如果使用自增id算法,会有一个问题就是不法分子是可以穷举你的短链地址的。
原理就是将10进制数字转为62进制,那么他人也可以使用相同的方法遍历你的短链获取对应的原始链接。
打个比方说:和 ,这两个短链网站,分别从a3300 - a3399,能够试下来多次返回正确的url。所以这些方法生成的短链对于使用者来说似乎是不安全的。
摘要算法,其实就是hash算法吧,一说hash你们可能感觉很low,但是事实上hash可能是最优解。比如: 和 连续生成的url发觉并没有规律,很有可能就是使用hash算法来实现。
普通随机数算法,这种算法生成的东西和摘要算法一样,但是碰撞的机率会大一些。因为摘要算法其实是对url进行hash生成,随机数算法就是简单的随机生成,数量一旦上来必然会导致重复。
综合以上,我选择最low的算法:摘要算法。
实现储存方案数据库储存方案短网址基础数据采用域名和后缀分开储存的方式。另外域名须要分辨 HTTP 和 HTTPS,hash方案针对整个链接进行hash而不是不仅域名外的链接。域名单独保存可以用于剖析当前域名下链接的使用情况。
增加当前链接有效期数组,一般有短链需求的可能是相关活动或则热点风波,这种短链在一段时间内会很活跃,过了一定时间风潮会持续衰退。所以没有必要将这些链接永久保存降低每次查询的负担。
对于过期数据的处理,可以在新增短链的时侯判定当前短链的失效日期,将每晚抵达失效日期的数据在HBase单独建一张表,有新增的时侯判定失效日期放在对应的HBase表中即可,每天只用处理当日HBase表中的失效数据。
数据库基础表如下:
字段释义:
缓存方案
个人觉得对于几百个G的数据量都置于缓存肯定是不合适的,所以有个折中的方案:将最近3个月内有查询或则有新增的url装入缓存,使用LRU算法进行热更新。这样近来有使用的发机率会命中缓存,就不用走库。查不到的时侯再走库更新缓存。
对于新增的链接就先查缓存是否存在,缓存不存在再查库,数据库早已分表了,查询的效率也不会很低。
查询的需求是用户拿着短链查询对应的真实地址,那么缓存的key只能是短链,可以使用 KV的方式储存。
番外虽然也可以考虑别的储存方案,比如HBase,HBase作为NOSQL数据库,性能上仅次于redis并且储存成本比redis低好多个数量级,存储基于HDFS,写数据的时侯会先先写入显存中,只有显存满了会将数据刷入到HFile。
读数据也会快,原因是因为它使用了LSM树型结构,而不是B或B+树。

HBase会将近来读取的数据使用LRU算法装入缓存中,如果想提高读能力,可以调大blockCache。
其次,也可以使用ElasticSearch,合适的索引规则疗效不输缓存方案。
是否有分库分表的须要?
对于单条数据10b以内,一亿条数据总容量大概为 953G,单表肯定没法稳住如此大的量,所以有分表的须要,如果你对服务很有信心2年内能达到这个规模,那么你可以从一开始设计就考虑分表的方案。
那么怎样定义分表的规则呢?
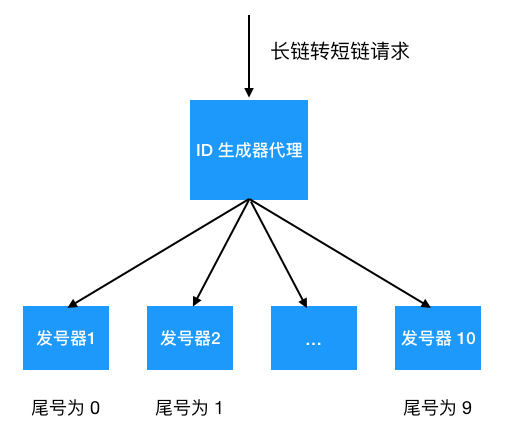
如果根据单表500万条记录来算,总计可以分为20张表,那么单表容量就是47G,还是挺大,所以考虑分表的 key 和单表容量,如果分为100张表这么单表容量就是10G,并且通过数字后缀路由到表中也比较容易。可以对short_code 做encoding编码生成数字类型之后做路由。
如何转跳
当我们在浏览器里输入 时
DNS首先解析获得 的IP地址
当 DNS 获得 IP 地址之后(比如:12.34.5.32),会向这个地址发送 HTTP GET 请求,查询短码 a3300
服务器会通过短码a3300获取对应的长 URL
