
sed命令是隐性的全局命令
参数s:替换文字内字符串。最多与两个地址参数配合。
1.在包含字符串test的任意行上,将111替换成222
#sed '/test/s/111/222/g' sample.txt
2.以下三个命令相等,先在包含字符串test的任意行上,将111替换成222,再将字符f替换成hello
#sed '/test/s/111/222/g ; s/f/hello/g' sample.txt
#sed -e '/test/s/111/222/g' -e 's/f/hello/g' sample.txt
将要执行的所以编译命令装入在文件中
#more scher
/test/s/111/222/g
s/f/hello/g' sample.txt
#sed -f scher sample.txt
3.替换每行的第N个匹配(示例为替换第八个字符)
#sed ‘s/test/TEST/8' sample.txt
4在第三到第五行前加入hello
#sed '3,5 s/^/hello/' sample.txt
参数d: 删除数据行。最多与两个地址参数配合。
1.删除第一到三行
#sed ‘1,3d’sample.txt
2.删掉带user的行
#sed ‘/user/d’sample.txt
3.删掉带有a或b字符的行
#sed '/[ab]/d' sample.txt
参数a:将资料添加到指定文件后。最多与一个地址参数配合。
1.在富含FTP的行前面插入一行123
#sed -e '/FTP/a\123' sample.txt
2.在第五行后插入123
#sed -e '5 a\123' sample.txt
参数i将资料插入到指定文件前。最多与一个地址参数配合。
1.在富含FTP的行后面插入一行123
#sed -e '/FTP/i\123' sample.txt
2.在第五前后插入123
#sed -e '5 i\123' sample.txt
参数c:改变文件中的数据。最多与两个地址参数配合。
1.以使用者输入的数据代替数据
eg:将文件1到100行的数据替换成test
#sed -e '1.100c test' sample.txt
2.把a和b替换成hello
#sed '/[a b]/c\hello' sample.txt
参数p:打印出资料。最多与两个地址参数配合。
1.打印出富含a或b的行
#sed -n -e '/[ab]/p' sample.txt
参数r:读入他的档案内容到文件中。最多与一个地址参数配合。
1.将temp.txt中的内容,搬至文件中富含AA字符串的数据行后(temp.txt中有内容)
#sed -e '/AA/r temp.txt' sample.txt
参数w:读入文件中的内容存入到另一文件中(temp.txt)。最多与一个地址参数配合。
1.将文件中含test字符串的数据行,copy至temp.txt档中存储(原temp.txt中无内容)
#sed -e '/test/w temp.txt' sample.txt
参数y:转换数据中的字符。最多与两个地址参数配合。
1.将文件中的大写字母替换成大写字母。
#sed -e 'y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/' sample.txt
其中前后字符个数必须相同.
参数!:表示不执行函数参数。
1.将文件中不仅important字符串,其余全删掉。
#sed -e '/important/!d' sample.txt
参数n:表示读入下一行数据。最多与两个地址参数配合。
解释:例如源文件为:
A
B
C
D
那么实际读入到pattern space的数据就为B D,因为她们分别为第一行A和第三行C的下一行.
1.输出源文件的质数行数据。
#sed -n -e 'n' -e 'p' sample.txt
或#sed -n 'n;p' sample.txt
这里-n是选项。‘’中的n才是参数。-n的意思是将数据输出的控制权转给指令,即只显示处理后的结果。
利用n将下一行资料(即:偶数行)取代pattern space的资料行(奇数行)
2.输出源文件的质数行数据。
#sed -n -e 'p' -e 'n' sample.txt
#sed -n 'p;n' sample.txt
参数q:表示跳离sed。最多与一个地址参数配合。
1.打印出富含a或b字符的行,一旦碰到数字,即刻停止复印。
#sed -n -e '/[0-9]/q' -e '/[a b]/p' sample.txt
参数=:表示印出资料的行数。最多与两个地址参数配合。

1.印出文件资料中的行数。
#sed -e ‘=’ sample.txt
参数#:表示对文字的注释。
参数N:表示添加下一笔资料到pattern space内。最多与两个地址参数配合。(添加下一笔:添加一笔资料后,继续添加这个资料的下一行数据到pattern space内)
1,将文件中的数据合并。文件内容如下:
UNIX
LINUX
#sed -e 'N' -e's/\n/\,/g' sample.txt
结果如下:
UNIX,LINUX
参数D:表示删掉pattern space内的第一行资料。最多与两个地址参数配合。
参数P:打印出pattern space内的第一行资料。
#sed -n -e 'N' -e 'P' sample.txt
利用N将下一行资料(即:偶数行)添加到pattern space内,在借助P复印出质数行。
解释过程:由于N的作用,使得每次添加一条资料到pattern space后,先不执行操作,而是继续添加这个资料的下一行到pattern space内,
然后P参数复印出第一行资料。
参数h:表示暂存pattern space的内容至hold space(覆盖)。最多与两个地址参数配合。
参数H:表示暂存pattern space的内容至hold space(添加)。最多与两个地址参数配合。
参数g:表示将hold space的内容放回至pattern space内。(覆盖掉原pattern space内的数据)
参数G:表示将hold space的内容放回至pattern space内。(添加大到原pattern space数据然后)
1.将文件中所有空行删掉,并在每一行前面降低一个空行。
sed '/^$/d;G' sample.txt
2.将文件中所有空行删掉,并在每一行前面降低两个空行。
sed '/^$/d;G;G' sample.txt
参数x:表示交换hold space与pattern space内的数据。
1.将文件第三行的数据替换成第一行的数据。
#sed -e '1h' -e '3x' sample.txt
参数b:
参数t:
一些示例:
1.在匹配样式test的行之前插入一空行。
#sed '/test/i\ ' sample.txt
#sed '/test/{x;p;x}' sample.txt
2.在匹配样式test的行以后插入一空行。
#sed '/test/a\ ' sample.txt
#sed '/test/G' sample.txt
3.为文中每一行进行编号。
#sed = sample.txt | sed 'N;s/\n/:/'
#sed = sample.txt | sed 'N;s/\n/\t/'
4.为文中每一行进行编号,但只显示非空行的编号。
#sed /./= sample.txt | sed '/./N;s/\n/:/'
.不匹配空。将sample.txt中所有非空行编号,然后取出不包含非空行的行及其下一行数据装入pattern space内,再将空格替换成:)
5.计算文件行数。
Sed命令是linux下的一个特别有用的命令,特别是在shell脚本中常常会使用到他。
熟悉他你会感觉特别有趣哦!
1.sed -n '2'p filename
打印文件的第二行。
2.sed -n '1,3'p filename
打印文件的1到3行
3. sed -n '/Neave/'p filename
打印匹配Neave的行(模糊匹配)
4. sed -n '4,/The/'p filename
在第4行查询模式The
5. sed -n '1,$'p filename
打印整个文件,$表示最后一行。
6. sed -n '/.*ing/'p filename
匹配任意字母,并以ing结尾的词组(点号不能少)
7 sed -n / -e '/music/'= filename
打印匹配行的行号,-e 会复印文件的内容,同时在匹配行的后面标志行号。-n只复印出实际的行号。
8.sed -n -e '/music/'p -e '/music/'= filename
打印匹配的行和行号,行号在内容的下边
9.sed '/company/' a\ "Then suddenly it happend" filename
选择富含company的行,将前面的内容"Then suddenly it happend"加入下一行。注意:它并不改变文件,所有操作在缓冲区,如果要保存输出,重定向到一个文件。
10. sed '/company/' i\ "Then suddenly it happend" filename
同9,只是在匹配的行前插入
11.sed '/company/' c\ "Then suddenly it happend" filename
用"Then suddenly it happend"替换匹配company的行的内容。
12.sed '1'd ( '1,3'd '$'d '/Neave/'d) filename
删除第一行(1到3行,最后一行,匹配Neave的行)
13.[ address [,address]] s/ pattern-to-find /replacement-pattern/[g p w n]
s选项通知s e d这是一个替换操作,并查询pattern-to-find,成功后用replacement-pattern替换它。
替换选项如下:
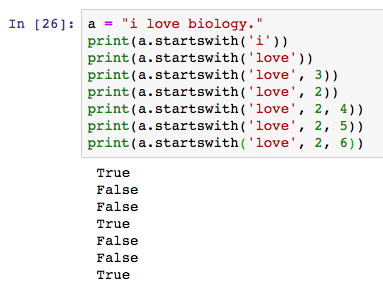
g 缺省情况下只替换第一次出现模式,使用g选项替换全局所有出现模式。
p 缺省s e d将所有被替换行写入标准输出,加p选项将使- n选项无效。- n选项不复印输出结果。
w 文件名使用此选项将输出定向到一个文件。(注意只将匹配替换的行写入文件,而不是整个内容)
14.sed s'/nurse/"hello "&/' filename
将'hello '增加到'nurse' 的后面。
15. sed '/company/r append.txt' filename
在匹配company的行的下一行开始加入文件append.txt的内容。
16. sed '/company/'q filename
首次匹配company后就退出sed程序
只所以看sed命令,是因为我遇见了这个一个问题。
网上有很多教程,他们发表了好多程序代码,但是作者为了解释便捷,都对程序作了行号编码,就像下边这样:
代码::
1:#!/bin/bash
2:#rename file extesions
3:#
4:# rfe old_extensions new_extension
假设这个文件名是tmp,那么我们可以使用下边的命令来去除这个行号和逗号(:)
代码::
sed -e s'/^[0-9]\{1,\}://g' tmp
不过里面的命令的命令有一个缺点,那就是假如这个行号不是数字开头,而是有空格的话,那就须要更改匹配规则,规则应当更改为匹配第一个非空白字符是数字开始,后面接一个引号的配对。命令如下:
代码::
sed -e s'/^[^0-9a-zA-Z]*[0-9]\{1,\}://g' tmp
这令我很兴奋,于是想瞧瞧sed究竟有多厉害,看了之后,明白的是不是sed有多厉害,就像awk一样,他们只是把正规表达式用到了极至。
以 Redhat6.0 为测试环境
事实上在solaris下的sed命令要比linux强,但由于没有测试
环境,我这儿只给在linux下经过测试的用法。
★ 命令行参数简介
★ 首先假定我们有这样一个文本文件 sedtest.txt
★ 输出指定范围的行 p
★ 在每一行上面降低一个制表符(^I)
★ 在每一行前面降低--end
★ 显示指定模式匹配行的行号 [/pattern/]=
★ 在匹配行前面降低文本 [/pattern/]a\ 或者 [address]a\
★ 删除匹配行 [/pattern/]d 或者 [address1][,address2]d
★ 替换匹配行 [/pattern/]c\ 或者 [address1][,address2]c\
★ 在匹配行后面插入文本 [/pattern/]i\ 或者 [address]i\
★ 替换匹配串(注意不再是匹配行) [addr1][,addr2]s/old/new/g
★ 限定范围后的模式匹配
★ 指定替换每一行中匹配的第几次出现
★ &代表最后匹配
★ 利用sed更改PATH环境变量
★ 测试并提升sed命令运行效率
★ 指定输出文件 [address1][,address2]w outputfile
★ 指定输入文件 [address]r inputfile
★ 替换相应字符 [address1][,address2]y/old/new/
★ !号的使用
★ \c正则表达式c 的使用
★ sed命令中正则表达式的复杂性
★ 转换man指南成普通文本格式(新)
★ sed的man指南(用的就是里面的方式)
★ 命令行参数简介
sed
-e script 指定sed编辑命令
-f scriptfile 指定的文件中是sed编辑命令
-n 寂静模式,抑制来自sed命令执行过程中的冗余输出信息,比如只
显示这些被改变的行。
不明白?不要紧,把这种丑恶丢到一边,跟我往下走,不过下边的介绍里
不包括正则表达式的解释,如果你不明白,可能有点麻烦。
★ 首先假定我们有这样一个文本文件 sedtest.txt
cat > sedtest.txt
Sed is a stream editor
----------------------
A stream editor is used to perform basic text transformations on an input stream
--------------------------------------------------------------------------------
While in some ways similar to an editor which permits scripted edits (such as ed
)
,
--------------------------------------------------------------------------------
-
-
sed works by making only one pass over the input(s), and is consequently more
-----------------------------------------------------------------------------
efficient. But it is sed's ability to filter text in a pipeline which particular
l
y
--------------------------------------------------------------------------------
-
★ 输出指定范围的行 p other types of editors.
sed -e "1,4p" -n sedtest.txt
sed -e "/from/p" -n sedtest.txt
sed -e "1,/from/p" -n sedtest.txt
★ 在每一行上面降低一个制表符(^I)
sed "s/^/^I/g" sedtest.txt
注意^I的输入方式是ctrl-v ctrl-i
单个^表示行首
★ 在每一行前面降低--end
sed "s/$/--end/g" sedtest.txt
单个$表示行尾
★ 显示指定模式匹配行的行号 [/pattern/]=
sed -e '/is/=' sedtest.txt
1
Sed is a stream editor
----------------------
3
A stream editor is used to perform basic text transformations on an input stream
--------------------------------------------------------------------------------
While in some ways similar to an editor which permits scripted edits (such as ed
)
,
--------------------------------------------------------------------------------
-
-
7
sed works by making only one pass over the input(s), and is consequently more
-----------------------------------------------------------------------------
9
efficient. But it is sed's ability to filter text in a pipeline which particular
l
y
--------------------------------------------------------------------------------
-
-
意思是剖析sedtest.txt,显示这些包含is串的匹配行的行号,注意11行中出现了is字符串
这个输出是面向stdout的,如果不做重定向处理,则不影响原先的sedtest.txt
★ 在匹配行前面降低文本 [/pattern/]a\ 或者 [address]a\
^D
sed -f sedadd.script sedtest.txt
Sed is a stream editor
A stream editor is used to perform basic text transformations on an input stream
While in some ways similar to an editor which permits scripted edits (such as ed
)
,
--------------------------------------------------------------------------------
-
-
sed works by making only one pass over the input(s), and is consequently more
-----------------------------------------------------------------------------
efficient. But it is sed's ability to filter text in a pipeline which particular
l
y
--------------------------------------------------------------------------------
-
-
[scz@ /home/scz/src]> sed -e "a\\
+++++++++
---------------------------------------------
找到包含from字符串的行,在该行的下一行降低+++++++++。
这个输出是面向stdout的,如果不做重定向处理,则不影响原先的sedtest.txt
很多人想在命令行上直接完成这个操作而不是多一个sedadd.script,不幸的是,这须要用?nbsp;
?nbsp;
续行符\,
[scz@ /home/scz/src]> sed -e "/from/a\\
> +++++++++" sedtest.txt
[scz@ /home/scz/src]> sed -e "a\\
> +++++++++" sedtest.txt
上面这条命令将在所有行后降低一个新行+++++++++
[scz@ /home/scz/src]> sed -e "1 a\\
> +++++++++" sedtest.txt
把下边这两行copy/paste到一个shell命令行上,效果一样
+++++++++" sedtest.txt
[address]a\ 只接受一个地址指定
对于a命令,不支持单冒号,只能用双引号,而对于d命令等其他命令,同时
★ 删除匹配行 [/pattern/]d 或者 [address1][,address2]d
sed -e '/---------------------------------------------/d' sedtest.txt
Sed is a stream editor
A stream editor is used to perform basic text transformations on an input stream
While in some ways similar to an editor which permits scripted edits (such as ed
)
,
sed works by making only one pass over the input(s), and is consequently more
efficient. But it is sed's ability to filter text in a pipeline which particular
l
y
sed -e '6,10d' sedtest.txt
删除6-10行的内容,包括6和10
sed -e "2d" sedtest.txt
删除第2行的内容
sed "1,/^$/d" sedtest.txt
删除从第一行到第一个空行之间的所有内容
注意这个命令很容易带来意外的结果,当sedtest.txt中从第一行开始并没有空行,则sed删
?nbsp;
?nbsp;
sed "1,/from/d" sedtest.txt
删除从第一行到第一个包含from字符串的行之间的所有内容,包括第一个包含
from字符串的行。
★ 替换匹配行 [/pattern/]c\ 或者 [address1][,address2]c\
sed -e "/is/c\\
**********" sedtest.txt
寻找所有包含is字符串的匹配行,替换成**********
**********
----------------------
**********
--------------------------------------------------------------------------------
While in some ways similar to an editor which permits scripted edits (such as ed
)
,
--------------------------------------------------------------------------------
-
-
**********
-----------------------------------------------------------------------------
**********
--------------------------------------------------------------------------------
-
sed -e "1,11c\\
**********" sedtest.txt----------------------
在1-12行内搜索所有from字符串,分别替换成****字符串
★ 限定范围后的模式匹配
sed "/But/s/is/are/g" sedtest.txt
对这些包含But字符串的行,把is替换成are
sed "/is/s/t/T/" sedtest.txt
对这些包含is字符串的行,把每行第一个出现的t替换成T
sed "/While/,/from/p" sedtest.txt -n
输出在这两个模式匹配行之间的所有内容
★ 指定替换每一行中匹配的第几次出现
sed "s/is/are/5" sedtest.txt
把每行的is字符串的第5次出现替换成are
★ &代表最后匹配
sed "s/^$/(&)/" sedtest.txt
给所有空行降低一对()
sed "s/is/(&)/g" sedtest.txt
给所有is字符串外降低()
sed "s/.*/(&)/" sedtest.txt
给所有行降低一对()
sed "/is/s/.*/(&)/" sedtest.txt
给所有包含is字符串的行降低一对()
★ 利用sed更改PATH环境变量
先查看PATH环境变量
[scz@ /home/scz/src]> echo $PATH
/usr/bin:/usr/bin:/bin:/usr/local/bin:/sbin:/usr/sbin:/usr/X11R6/bin:.
去掉尾部的{ :/usr/X11R6/bin:. }
[scz@ /home/scz/src]> echo $PATH | sed "s/^\(.*\):\/usr[/]X11R6\/bin:[.]$/\1/"
/usr/bin:/usr/bin:/bin:/usr/local/bin:/sbin:/usr/sbin
去掉中间的{ :/bin: }
[scz@ /home/scz/src]> echo $PATH | sed "s/^\(.*\):\/bin:\(.*\)$/\1\2/"
/usr/bin:/usr/bin/usr/local/bin:/sbin:/usr/sbin:/usr/X11R6/bin:.
[/]表示/失去特殊意义
\/同样表示/失去意义
\1表示子匹配的第一次出现
\2表示子匹配的第二次出现
\(.*\)表示子匹配
去掉尾部的:,然后降低新的路径
PATH=`echo $PATH | sed 's/\(.*\):$/\1/'`:$HOME/src
注意反冒号`和单冒号'的区别。
★ 测试并提升sed命令运行效率
time sed -n "1,12p" webkeeper.db > /dev/null
time sed 12q webkeeper.db > /dev/null可以看出前者比后者效率高。
[address]q 当碰上指定行时退出sed执行
★ 指定输出文件 [address1][,address2]w outputfile
sed "1,10w sed.out" sedtest.txt -n
将sedtest.txt中1-10行的内容讲到sed.out文件中。
★ 指定输入文件 [address]r inputfile
sed "1r sedappend.txt" sedtest.txt
将sedappend.txt中的内容附加到sedtest.txt文件的第一行以后
★ 替换相应字符 [address1][,address2]y/old/new/
sed "y/abcdef/ABCDEF/" sedtest.txt
将sedtest.txt中所有的abcdef大写字母替换成ABCDEF大写字母。
★ !号的使用
sed -e '3,7!d' sedtest.txt
删除3-7行之外的所有行
sed -e '1,/from/!d' sedtest.txt
找到包含from字符串的行,删除其后的所有行
★ \c正则表达式c 的使用
sed -e "\:from:d" sedtest.txt
等价于 sed -e "/from/d" sedtest.txt
★ sed命令中正则表达式的复杂性
cat > sedtest.txt
^\/[}]{.*}[\(]$\)
^D
如何能够把该行替换成
\(]$\)\/[}]{.*}^[
★ 转换man指南成普通文本格式(新)
man sed | col -b > sed.txt
sed -e "s/^H//g" -e "/^$/d" -e "s/^^I/ /g" -e "s/^I/ /g" sed.txt > sedman
txt
删除所有退格键、空行,把行首的制表符替换成8个空格,其余制表符替换成一个空格。
★ sed的man指南(用的就是里面的方式)
NAME
sed - a Stream EDitor
SYNOPSIS
sed [-n] [-V] [--quiet] [--silent] [--version] [--help]
[-e script] [--expression=script]
[-f script-file] [--file=script-file]
[script-if-no-other-script]
[file...]
DESCRIPTION
Sed is a stream editor. A stream editor is used to per-
form basic text transformations on an input stream (a file
or input from a pipeline). While in some ways similar to
an editor which permits scripted edits (such as ed), sed
works by making only one pass over the input(s), and is
consequently more efficient. But it is sed's ability to
filter text in a pipeline which particularly distinguishes
it from other types of editors.
OPTIONS
Sed may be invoked with the following command-line
options:
-V
--version
Print out the version of sed that is being run and
